








Readme |
Discord |
Instances |
User Showcase |
GitHub |
Documentation




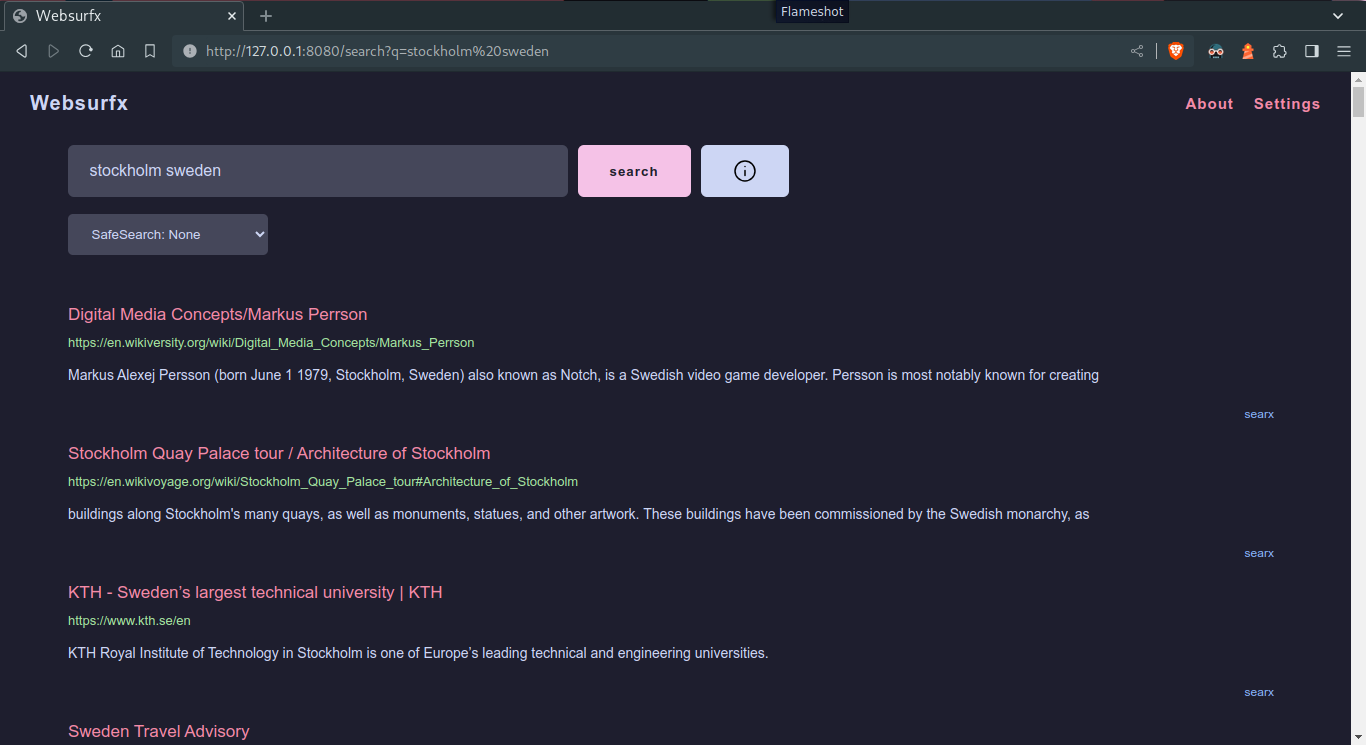
A modern-looking, lightning-fast, privacy-respecting, secure
meta search engine
(pronounced as websurface or web-surface /wɛbˈsɜːrfəs/.) written in Rust. It
provides a quick and secure search experience while completely respecting user
privacy.
Table of Contents
-
Getting Started
-
Feature Overview
-
Community



For a full list of publicly available community driven
websurfxinstances to test or for daily use. see Instances
- 🎨 Make Websurfx uniquely yours with the twelve color schemes provided by default. It also supports the creation of custom themes and color schemes in a quick and easy way, so unleash your creativity!
- 🚀 Easy to setup with Docker or on bare metal with various installation and deployment options.
- ⛔ Search filtering to filter search results based on four different levels.
- 💾 Different caching levels focusing on reliability, speed and resiliancy.
- ⬆️ Organic Search results (with ranking algorithm builtin to rerank the search results according to user’s search query.).
- 🔒 Different compression and encryption levels focusing on speed and privacy.
- 🧪 Experimental IO-uring feature for Linux operating systems focused on performance of the engine.
- 🔐 Fast, private, and secure
- 🆓 100% free and open source
- 💨 Ad-free and clean results
- 🌟 and lots more…
For full setup instructions, see: Installation
Before you can start building websurfx, you will need to have Cargo installed on your system. You can find the installation instructions here.
To get started with Websurfx, clone the repository, edit the config file, which is located in the websurfx/ directory, and install the Redis server by following the instructions located here and then run the websurfx server and redis server using the following commands:
git clone https://github.com/neon-mmd/websurfx.git
cd websurfx
git checkout stable
cargo build -r
redis-server --port 8082 &
./target/release/websurfxOnce you have started the server, open your preferred web browser and navigate to http://127.0.0.1:8080 to start using Websurfx.
Note
- The project is no longer in the testing phase and is now ready for production use.
- There are many features still missing, like
support for image search,different categories,quick apps, etc., but they will be added soon as part of future releases.
For full configuration instructions, see: Configuration
Websurfx is configured through the config.lua file, located at websurfx/config.lua.
For full theming and customization instructions, see: Theming
Websurfx comes loaded with several themes and color schemes, which you can apply and edit through the config file. It also supports custom themes and color schemes using CSS, allowing you to make it truly yours.
Note
Currently, we do not support other languages, but we will start accepting contributions regarding language support in the future. We believe language should never be a barrier to entry.
At present, we only support x86_64 architecture systems, but we would love to have contributions that extend to other architectures as well.
The primary purpose of the Websurfx project is to create a fast, secure, and privacy-focused meta-search engine. There are numerous meta-search engines available, but not all guarantee the security of their search engines, which is critical for maintaining privacy. Memory flaws, for example, can expose private or sensitive information, which is understandably bad. There is also the added problem of spam, ads, and inorganic results, which most engines don’t have a full-proof answer to. Until now. With Websurfx, I finally put a full stop to this problem. Websurfx is based on Rust, which ensures memory safety and removes such issues. Many meta-search engines also lack important features like advanced picture search, required by graphic designers, content providers, and others. Websurfx improves the user experience by providing these and other features, such as proper NSFW blocking and micro-apps or quick results (providing a calculator, currency exchanges, etc. in the search results).
Websurfx is distributed under the AGPLv3 license to keep the source code open and transparent. This helps keep malware, telemetry, and other dangers out of the project. AGPLv3 is a strong copyleft license that ensures the software’s source code, including any modifications or improvements made to the code, remains open and available to everyone.
Websurfx is based on Rust due to its memory safety features, which prevent vulnerabilities and make the codebase more secure. Rust is also faster than C++, contributing to Websurfx’s speed and responsiveness. Finally, the Rust ownership and borrowing system enables secure concurrency and thread safety in the program.
We are looking for more willing contributors to help grow this project. For more information on how you can contribute, check out the project board and the CONTRIBUTING.md file for guidelines and rules for making contributions.
For full details and other ways you can help out, see: Contributing
If you use Websurfx and would like to contribute to its development, we’re glad to have you on board! Contributions of any size or type are always welcome, and we will always acknowledge your efforts.
Several areas that we need a bit of help with at the moment are:
- Better and more color schemes: Help fix color schemes and add other famous color schemes.
- Improve evasion code for bot detection: Help improve code related to evading IP blocking and emulating human behaviors located in everyone’s engine file.
- Logo: Help create a logo for the project and website.
- Docker Support: Help write a Docker Compose file for the project.
- Submit a PR to add a new feature, fix a bug, update the docs, add a theme, widget, or anything else.
- Star Websurfx on GitHub.
Note
We welcome any contributions to the documentation as this will benefit everyone who uses this project.
Coming soon! 🙂.
Contributions are welcome from anyone. It doesn’t matter who you are; you can still contribute to the project in your own way.
Check out this video by Mr. Nick on how to contribute.
If you are a developer, have a look at the CONTRIBUTING.md document for more information.
Websurfx is licensed under the AGPLv3 license.
We would like to thank the following people for their contributions and support:
Contributors

Stargazers


Thank you for Visiting
 https://github.com/neon-mmd/websurfx
https://github.com/neon-mmd/websurfx


















































